Away Day 2024 recap
30 May 2024

The DSC Away Day is an annual get together that is organised exclusively for our Affiliate members. There were 40 people in attendance from a diverse range of faculties, including the Faculty of Humanities (FgW), Faculty of Medicine (AUMC), Faculty of Social and Behavioural Sciences (FMG), Faculty of Science (FNWI) and UvA Executive Staff.
We started the morning with engaging presentations by our two speakers Prof. Paul Groth (Professor of Algorithmic Data Science, UvA) and Dr. Colette Bos (Programme Director, Netherlands eScience Center), on the topic of FAIR data and software implementation.


Participants were then given a choice to attend either a FAIR Data Implementation brainstorm, or a data science annotation-athon!
FAIR Data Management brainstorm
Following a refreshing post-lunch walk in the Goois Nature Reserve, participants were tasked with creating an inventory of all FAIR data management activities at their respective institutes with respect to (a) tools (b) infrastructure, and (c) policy. Participants will come together at a later date to compile a future planning document based on this inventory.


Data Annotation-athon
Participants worked in groups to annotate datasets together, with the goal of creating a high quality and well-labelled dataset by the end of the day.
Attendees could choose to work on one of three different datasets. The results were impressive:
- Dataset 1 (Tweets and social media posts by selected political parties, led by Justin Ho): 438 annotations done over 210 media posts, which will then be used as a gold standard to validate the prediction of a fine-tuned large language model to address the differences in social media use by political parties.
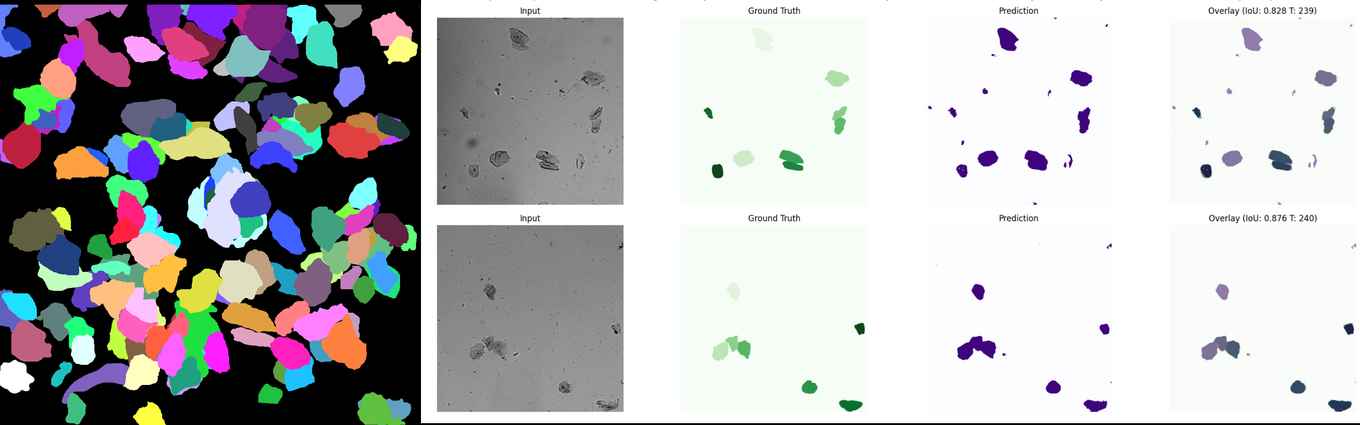
- Dataset 2 (Images of cells, led by Joachim Goedhart): 720 cells annotated, and the data was then successfully used to train a U-Net deep learning network for image segmentation.
- Dataset 3 (Student thesis abstracts, led by Difeng Guo): 711 annotations, which will be used to develop an automated algorithm to estimate the number of students who have studied abroad
At the end of the day, we collectively reflected on the challenges and learnings of data annotation. Some of these thoughts included:
- Labels need to be clearly defined so that personal preference when facing ambiguous data points can be minimised
- It can be error prone work. Expert knowledge and using the right tooling is important
- Annotating is a cultural and context specific exercise
- Is manual annotation still the ‘gold standard’? In some cases, an AI-based classification system can outperform a minimally trained annotator
- Large codebooks can be complicated to use
A very big thank you to everyone who attended the Away Day, particularly our morning symposium presenters and dataset contributors, for once again making this day a big success!